いいえ、これはゲームのブログではありませんが、ゲームから始めましょう。もしあなたがPCゲームに夢中なら、ゲームに最適なグラフィックカードには通常、GDDR(GDDR6など)と呼ばれるクラスのダイナミック・アクセス・メモリが搭載されていることをご存じでしょう。1枚のグラフィックスカードに数十ギガバイトのローカルGDDR6メモリが搭載されていることがありますが、これはGPUに接続されており、マザーボード上のメインメモリとは独立しています。この記事では、GDDRとは何か、なぜそれほど重要なのかについて説明します。 ネタバレ注意:答えはゲームのためではありません。
GDDRメモリとは?
GDDRはGraphics Double Data Rate(グラフィックス・ダブル・データ・レート)の略で、その名前からダブル・データ・レート・メモリの一種であることがわかります。ビット(1と0)を格納するメモリセルのアレイを持ち、行と列で構成されています。これは、PCマザーボードや高性能ノートPCに搭載されている通常のDDRメモリとよく似ています。違いは、メモリIC内部でセルにアクセスする速度と、メモリICから接続されたホスト・プロセッサにデータを転送する速度の違いにある。これを図1に、GDDRメモリのアーキテクチャのハイレベル・ブロック図を示します。
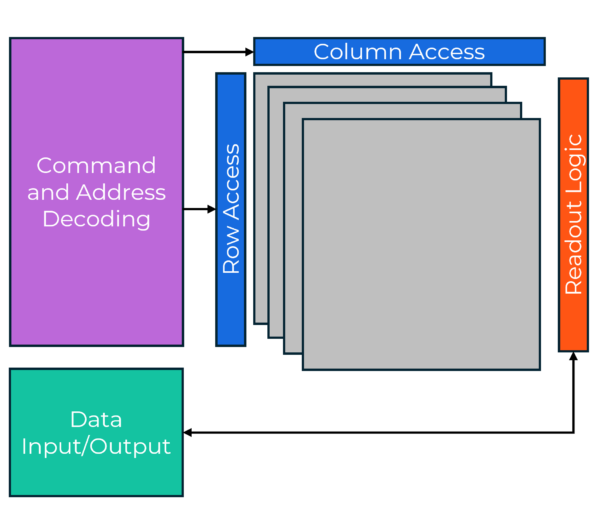
図1:GDDRメモリのアーキテクチャのブロック図。
見てわかるように、デバイスはメモリ・バンク(1と0を格納)を含む。メモリ・バンクのある位置からの読み出し、またはメモリ・バンクのある位置への書き込みのプロセスは、コマンドおよびアドレス・デコード・ブロックによって可能になり、このブロックは、特定のロウ・アクセス回路およびカラム・アクセス回路と連動して動作します。具体的には、メモリのあるアドレスがホスト・コントローラによって読み出されるとき、これらの行アクセス回路と列アクセス回路は、メモリ内の1つの座標(すなわち、スマートフォンのお気に入りのマップ・アプリで入力するアドレスに非常によく似たアドレス)または座標のセットをピンポイントで特定するために、非常に高速に起動される。その後、読み出し回路がこれらの位置のデータをフェッチし、データ入出力ロジックブロックを通して送信するために使用される。
上記は、基本的に通常のDDRメモリも同様に機能する方法であり、それゆえGDDRとDDRは類似している。GDDRと異なるのは、それが非常に高速に設計されていることだ。メモリの中身は、たとえば高解像度画像をレンダリングするためのベクターになります。非常に高性能なゲームグラフィックスをレンダリングするプロセスでは、大量のデータに繰り返しアクセスし、このデータに対して非常に高速で繰り返し計算を実行する必要があります。
グラフィック・プロセッシング・ユニット(GPU)とGDDRメモリの典型的な接続を図2に示します。

図2:グラフィック・プロセッシング・ユニット(GPU)とGDDRメモリの接続。
ユーザーのディスプレイにグラフィックを表示するために、GPUは表示される画像を表す大規模なデータセットに対して繰り返し数値計算を行い、このデータはGDDRメモリに格納される。この計算自体は、一般的なCPUの汎用計算よりも柔軟性に欠けるが、これこそが、通常のCPUよりもはるかに高速に実行できる理由である。
大規模なデータセットに対して繰り返し同様の計算を実行した結果、メモリへの一連の読み書きのトランザクションに変換される。そしてこれらのトランザクションは、GPUとメモリ間の小さな相互接続ワイヤーを介した高速デジタルデータの転送によって発生します。例えば、最新のGDDR6リンクは、16 Gbps SerDesのような速度に簡単に頼ることができますが、多数のピンにまたがっています。
GDDRメモリとDDRメモリの技術的な違い
GDDRメモリはDDRメモリに似ていますが、同じではありません。ここでは、2種類のメモリの技術的な違いを3つ示します。
BANDWIDTH
これについてはすでに前述しました。一般的な GDDR6 DRAM デバイスは、ピンあたり 16 Gbps で動作します。また、1 つの DRAM につき 2 つのメモリチャネルがあり、それぞれが 16 本の DQ ピンを含むため、1 つの DRAM デバイスの総スループットは 512 Gbps になります。対照的に、最新のDDR5 DRAMデバイスは、ピン当たり6.4 Gbpsで動作します。
ルーティング・スタイルと接続方式
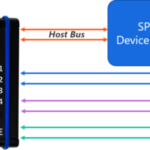
2つのメモリ・クラス間の内部アクセス・アーキテクチャの違いを別にすれば、GDDRメモリがDDRメモリより優れている点は、マルチドロップ構成ではなく、通常はポイント・ツー・ポイント構成で接続されることである。つまり、各ホスト・コントローラ・ポートは、1 つの単一メモリ・デバイスにのみ接続されます。図 3 に、2 つの接続方式の違いを説明します。
図3:(a)GDDRメモリのポイント・ツー・ポイント構成、(b)DDRメモリのマルチドロップ構成
DDR メモリはマルチドロップ構成で接続されるため、メモリコントローラと任意の DRAM デバイス間の PCB トレースは、メモリコントローラと GDDR メモリ間に接続される対応するトレースよりも、はるかに原始的ではありません。DDR トレースは、それに接続されるすべての負荷のインピーダンスのミスマッチが避けられないため、不連続性を持つことが多く、その結果、信号の反射や波形の歪みが生じます。このため、DDRトレースが動作可能な最大クロック速度が制限されます。
一方、GDDRメモリのアドレス・バスは、GPU上の対応するピンのみに接続されています。そのため、少なくとも原理的には、トレースのシグナルインテグリティを最適化し、トレース上に不連続がないことを保証する機会が増えます。反面、GDDR ではトレースの帯域幅がはるかに広いため、小さなジオメトリの不完全性に も敏感に反応します。ビア内の機能しないパッドの除去忘れのような、一見取るに足らないレイアウト・エラーでさえ、GDDRリンクの性能劣化につながる可能性があります。
プロトコルの違い
DDR プロトコルは GDDR プロトコルとは異なるため、ホストコントローラの設計も異なる。これらの違いの詳細はこの記事の範囲外であるが、以下のようなものがある:
- – フォワード・クロックの数と種類が異なる
- – コマンド・バス幅とアドレス・バス幅が異なる
- – データとストロボの配置が異なる
GDDRがこれほど重要な理由とは?
大学でニューラルネットワークの授業を受けたことがあるなら、学年末の課題はおそらくグラフィックカードで行われたことだろう。これこそが、GDDRが最近重要になってきている理由なのだ。結局のところ、ニューラルネットワークの訓練や実行に必要な計算は、ゲームアプリケーションのビデオ処理に必要な計算とコンセプトが非常に似ている。すなわち、反復的で類似した計算を、大規模なデータセットに対して非常に速いペースで実行しなければならない。これは次の2つのことを意味する。
- GPUアーキテクチャは、人工知能(AI)アプリケーションや機械学習(ML)に最適であり、CPUアーキテクチャではない。
- GDDRメモリ(高帯域幅と最適化されたアーキテクチャを持つ)は、AIとMLに最適であり、DDRメモリではない。
さらに、モバイル端末でもAI処理を追加しようとする多大な推進力により、コンピュータ・アーキテクチャは劇的に変化している。高帯域幅のメモリ実装を実現する方法は他にもあるが、GDDRは(他の競合ソリューションと比較して)低コストで優れた選択肢となる。 AI以外にも、多くのネットワーキング・アプリケーションや車載アプリケーションが、より高速なメモリ・アーキテクチャを必要としている。端的に言えば、CPUとGPUの処理能力は、メモリとの間の転送速度を向上させる能力をはるかに上回っている。つまり、車載、ネットワーキング、産業など、いくつかのアプリケーションでは、メモリー・アーキテクチャがボトルネックになっているのだ。GDDRメモリは、このギャップを解決する大きな可能性を秘めたソリューションです。GDDRメモリはDDRメモリよりもはるかに高速であり、高帯域幅メモリ(HBM)のようなエキゾチックなメモリ・ソリューションよりもはるかにコスト効率が高い。